


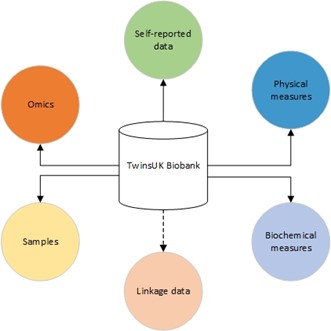
TwinsUK Data and Samples
Our cohort comprises extensive data within the areas below. These data are collected at multiple time points and continuously updated through new collections.
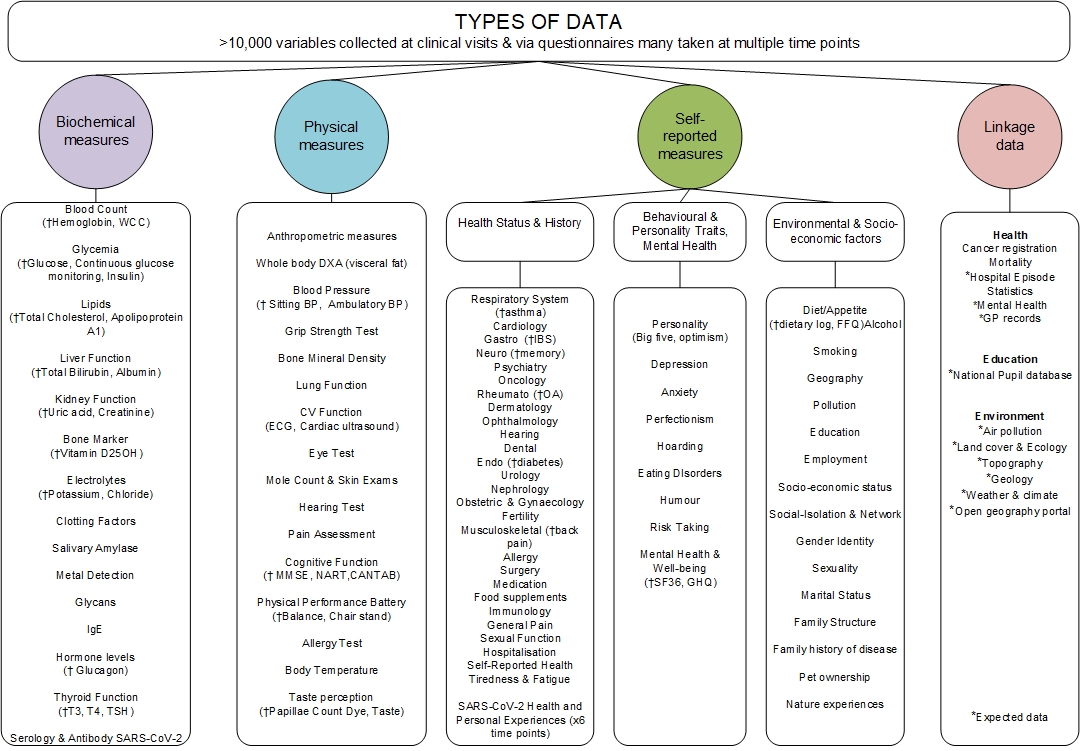
Phenotypes
Over 10,000 phenotypes have been collected on Twins since 1992 through detailed clinical assessments and longitudinal follow up visits. Data is also captured through targeted questionnaires including standardised longitudinal health questionnaires.
Click Here to download a detailed list of phenotypes available
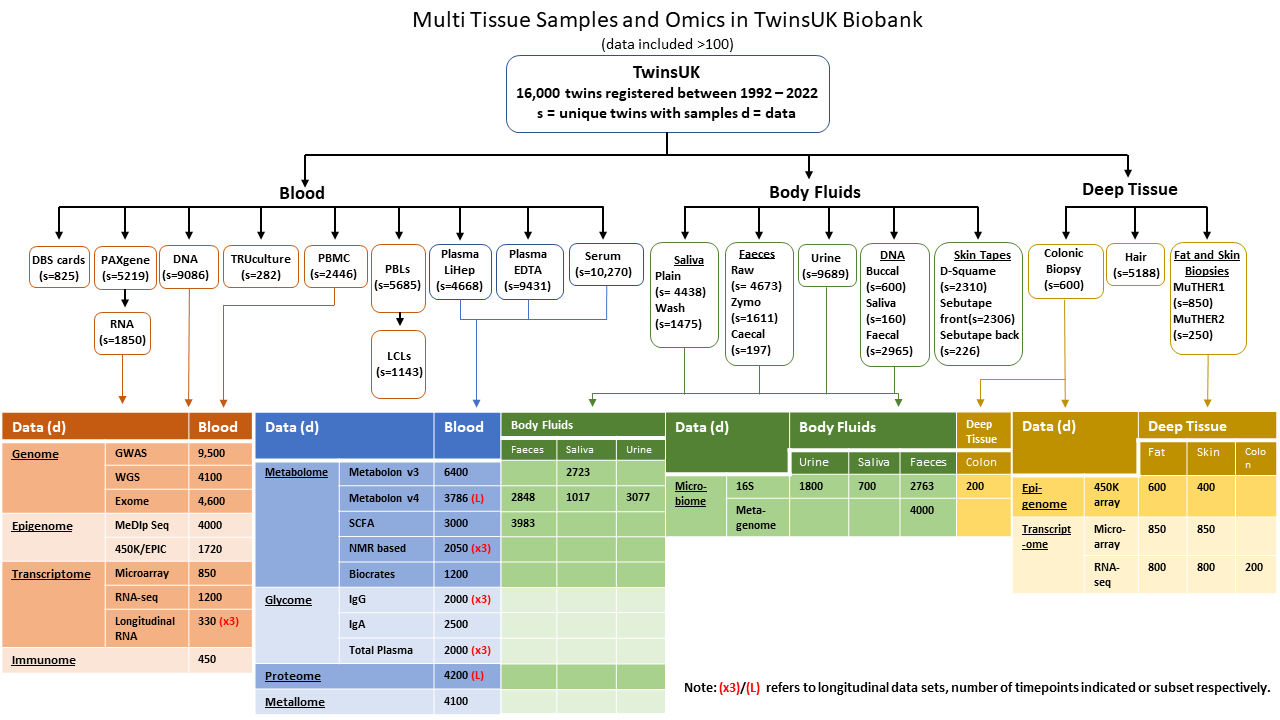
Samples & Omics
Approximately 800,000 twin samples from various types are stored within TwinsUK Biobank. Many of these are collected at multiple timepoints.
Multiple Omics data are available from samples from the resource. Most are accessible directly via TwinsUK data access processes. However, some of the omics data or subset of these data are publicly available on archived websites.
Click Here to download a detailed overview of the Omics data and the archived websites where they are stored.
New data
The TwinsUK study team collects new data from the twins via:
- Self-reported questionnaires, posted or emailed to the twins
- Clinical twin visits at the DTR
We will manage the collection of new data.
The implementation of questionnaires and twin visits will require funding and the final cost will be reviewed and agreed by all parties before the new data collection can commence.
Nutrition data (Predict Studies)
For access to our Predict studies data on:
- Berry et al, 2020 (https://www.nature.com/articles/s41591-020-0934-0)
- Ascinar et al, 2021 (https://pubmed.ncbi.nlm.nih.gov/33432175/) (PREDICT studies)
Please contact the Data and Access Collaboration Manager and include the following information:
- A brief aim of the project (1-2 lines)
- Summary of the data required (high level)
The committee will first assess if the data is available in a suitable linked format to address your hypothesis prior to completion of a full proposal.